Support Vector Machine with Numpy and Python
Intro
- Splitting the data in the best posible way - to get two data groups (categories).
- The key aspect is to split the data in as much optimal way as possible so that new data point can be precisely clasified.
- The data can be split in different ways. However, the line making the biggest gap between two classes is chosen as the separation line.
 source: wikipedia
source: wikipedia
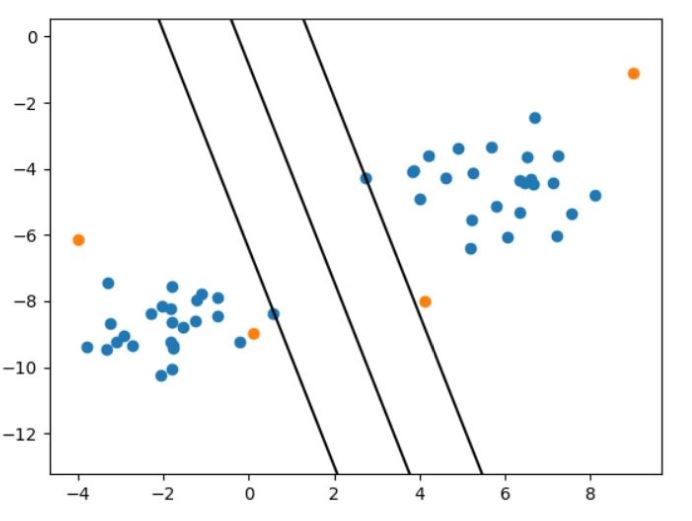
- Support vectors are extreme points of a specific data set of one category.
- Support vectors are those elements of the data that makes the biggest possible separation gap.
- Distance margin is the distance between support vectors from both data classes.
- Once we create an optimal separation line we can easily see which side a new data belongs to.
- The smaller the distance margin, the higher a chance of miss-classification is.
- If all of the data is placed in one line in 1D then we need to convert it into 2D with kernel.
- If one data of one class is sourrounded by data of second class we need to convert 2D into 3D with kernel.
Features
App includes following features:
Demo
- Training SVM model with Numpy.
- Getting new data: 4 items x 2 features.
- Labeling data to 1 or -1 relying on feature's values.
Setup
Script requires libraries installation:
- pip install pandas
- pip install numpy